DATAWISE : simplifier l’annotation des données pour mieux nourrir l’IA
L’entreprise Neovision et le LIRIS (CNRS / INSA Lyon / Université Claude Bernard Lyon 1) ont décidé d’unir leurs expertises autour de l’intelligence artificielle au sein du projet DATAWISE. Leur objectif : faciliter le travail d’annotation des données, carburant essentiel des modèles d’apprentissage profond.
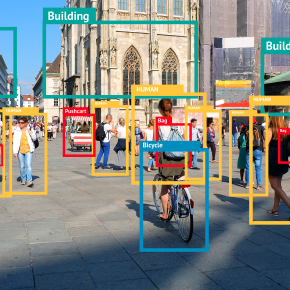
Neovision est une entreprise spécialisée en intelligence artificielle qui propose des solutions d’IA sur mesure à ses clients. Elle a notamment développé un outil, baptisé Tadaviz, qui vise à simplifier l’annotation de données, en particulier des images, grâce à des fonctionnalités de visualisation et d’automatisation.
« Nos modèles de deep learning ont besoin d’une masse suffisante de données pour représenter le phénomène qu’ils cherchent à analyser », expose Arthur Derathé, responsable de la production chez Neovision. « Or, pour obtenir des performances satisfaisantes dans le contexte technique de nos clients, par exemple des industriels, nous recourons à des méthodes d’apprentissage supervisé, c’est-à-dire à partir de données annotées. » Néanmoins, le travail d’annotation s’avère généralement répétitif et chronophage, tout en requérant une expertise métier élevée. L’objectif du logiciel Tadaviz développé par Neovision est donc de parvenir à un tel résultat en limitant l’intervention humaine.
Automatiser l’annotation des données
La volonté de Neovision de perfectionner cet outil a conduit l’entreprise à s’intéresser aux travaux menés dans le cadre de la thèse d’Alexandre Devillers, doctorant au Laboratoire d'InfoRmatique en Images et Systèmes d'information (LIRIS – CNRS / INSA Lyon / Université Claude Bernard Lyon 1) « Alexandre travaille sur des méthodes de deep learning auto-supervisées pour l’apprentissage de représentations d’images », indique Mathieu Lefort, enseignant-chercheur au sein du LIRIS et directeur de la thèse. « Les résultats obtenus ont permis d’optimiser les modèles à plusieurs niveaux, notamment quant à la structuration des informations extraites des images et à la capacité à généraliser ce qui a été appris à d’autres contextes. »
Autant d’éléments qui ont incité Neovision à se rapprocher du LIRIS et à répondre à un appel à projets du programme R&D Booster de la Région Auvergne-Rhône-Alpes. Cette démarche a abouti, en octobre 2024, au lancement du projet DATAWISE. « Un de nos objectifs est de réduire le coût de l’annotation, grâce à l’automatisation, ce qui représente un avantage concurrentiel significatif », présente Arthur Derathé. « Mais à travers ce partenariat avec le LIRIS, nous souhaitons également contribuer à faire avancer la connaissance scientifique dans le domaine. Nous prévoyons d’ailleurs, en plus des publications scientifiques quant aux résultats obtenus, de rendre le code open source à l’issue du projet. »

© Neovision
Augmentation des données et apprentissage actif
Afin d’atteindre les objectifs scientifiques de DATAWISE, l'équipe de recherche va explorer et développer davantage les travaux initiés dans le cadre de la thèse d'Alexandre Devillers. Ainsi, pour faciliter l’annotation d’un grand volume d’images, une première idée consiste à les regrouper de façon pertinente. Mais comment procéder de manière générique, sans même connaître l’objectif final d’un tel tri ? « Le défi est d’être capable d’extraire du "sens" à partir des images, d’identifier des relations entre elles », explique Mathieu Lefort. « Pour cela, il est possible d’appliquer des "augmentations" telles qu’un floutage plus ou moins prononcé, différents niveaux de zoom… Le but est alors de modifier les caractéristiques de l’image inutiles pour notre tâche et de conserver, au contraire, celles qui ont une valeur sémantique. »
Un autre axe de recherche s’attarde sur les ressources nécessaires aux modèles de deep learning employés. En revoyant leur architecture, peut-on diminuer les besoins en puissance de calcul et en temps d’apprentissage, tout en conservant des performances satisfaisantes ? De même, est-il possible de n’annoter qu’une partie des images disponibles ? « Sur ce point, l’apprentissage actif constitue une piste intéressante », note Mathieu Lefort. « Dans ce cas, le modèle peut lui-même orienter l’annotation en demandant de labelliser les données pour lesquelles il estime manquer d’informations. Il agit ainsi à la manière d’un enfant qui demanderait à ses parents des renseignements sur quelque chose qu’il ne connaît pas. »
Fluidifier l’expérience utilisateur
Enfin, DATAWISE vise à améliorer l’interface utilisateur de Tadaviz, en systématisant les interactions homme-machine en langage naturel à l’aide de LLM (Large Language Model). Le but est de simplifier et d’améliorer les interactions nécessaires entre l’utilisateur humain et l’outil. Celui-ci doit ainsi être capable de transformer la requête en une suite d’instructions et de fournir un résultat conforme à ce qu’attend l’utilisateur, qui peut alors être validé par un expert humain. « Nous sommes convaincus que l’expérience utilisateur des logiciels est à l’aube d’une transformation profonde », prédit Arthur Derathé. « Nous souhaitons emprunter ce virage en rendant Tadaviz plus ergonomique et intuitif, grâce à la compréhension du langage naturel. Et peut-être que dans quelques années, nos interfaces actuelles, reposant sur des clics et des mots-clés, nous paraîtront bien obsolètes. »